
Утилита TEXtractor предназначена для поиска в файлах формата RTF, FB2, а также на Веб-страницах слов и словосочетаний, заданных пользователем.
Единица извлечения — текстовый абзац или параграф (тег \par в RTF-файлах или теги <p>…</p> в FB2-файлах и на Веб-страницах).
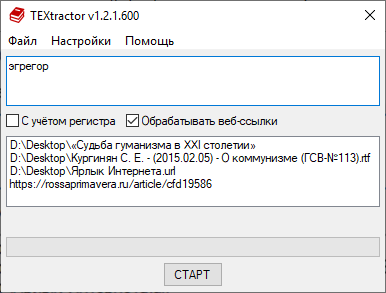
Окно программы состоит из двух областей: первое сверху — поле ввода слов или словосочетаний, подлежащих выборке; второе сверху — список источников, из которых производится выборка.
Формат записи слов или словосочетаний, подлежащих поиску, проще всего продемонстрировать на примерах.
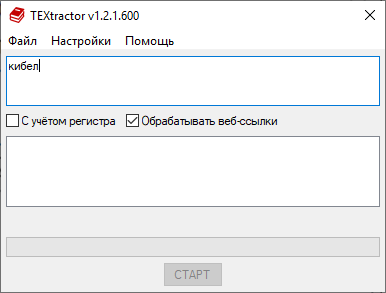
кибел — ищет все вхождения текста «кибел» (например, «Рея-Кибела», «кибелический», «кибелизм» и т.д.).
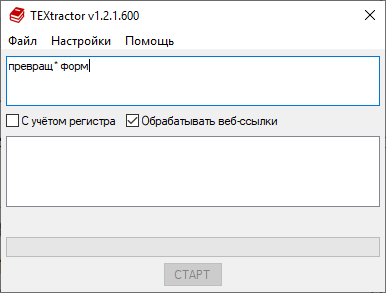
превращ* форм — ищет все вхождения текста «превращ* форм» (например, «превращенная форма», «превращенных форм», «превращения формы» и т.д.).
Несколько запросов можно объединять символом ; (точка с запятой):
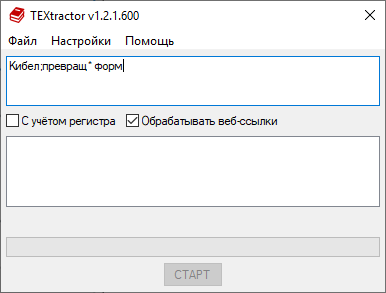
Кибел;превращ* форм — ищет одновременно перечисленные выше фрагменты в любых абзацах текста.
Если необходимо, чтобы искомые фрагменты были в пределах одного абзаца, то вместо ; (точка с запятой) используется & (амперсанд):
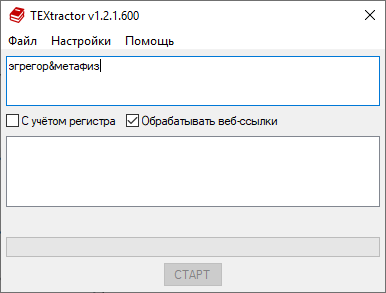
эгрегор&метафиз — создаст выборку из абзацев, в которых одновременно присутствуют эгрегор и метафиз.
По умолчанию искомый фрагмент ищется в любом месте слова, но если необходимо найти слова, начинающиеся с заданного фрагмента, то перед ним нужно поставить \ (обратную косую черту):
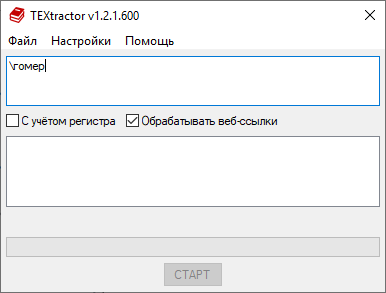
\гомер — найдет только слова, начинающиеся с «гомер» (а например, «многомерность» в выборку не попадёт).
По умолчанию поиск — регистронезависимый, т.е. для запроса «кибел» будет найдена как «Кибела», так и «кибела». Если же поставить галочку в поле «С учётом регистра», то будет найдена только «Кибела» (с большой буквы).
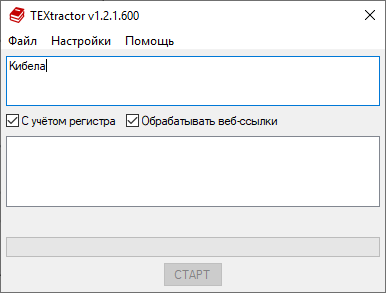
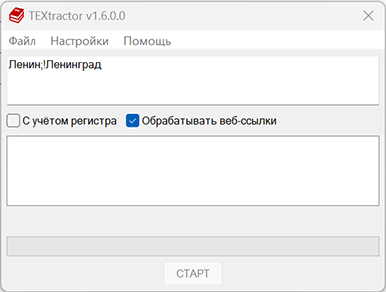
Кроме того, можно задавать слова-исключения — они начинаются со знака ! в начале слова. Например, если требуется искать вхождения слова «Ленин», но нежелательно включать в выборку «Ленинград» и его производные, то следует ввести Ленин;!Ленинград.
Программа поддерживает 4 типа источников:
- RTF-файлы;
- FB2-файлы;
- Веб-страницы по прямым ссылкам (см. «Веб-ссылки»);
- Веб-страницы через «Ярлык Интернета Windows» (см. «Веб-ссылки»);
- TEX-файлы (см. «Сохранение настроек»);
- Папки, содержащие какие-либо из вышеперечисленных типов источников (все источники в данных папках и подпапках будут обработаны рекурсивно).
Добавлять источники можно:
- перетаскиванием мышью (Drag & Drop) файлов и папок в поле источников;
- через стандартный диалог открытия папок
«Файл > Добавить папки… (Ctrl+O)»или файлов«Файл > Добавить файлы… (Ctrl+Shift+O)»; - через буфер обмена: скопируйте в буфер обмена папки и файлы через Проводник Windows, либо скопируйте текстовые пути (разделенные переводом строки) папок/файлов и вставьте их в поле ввода источников
«Файл > Добавить из буфера обмена (Ctrl+V)».
Удалить источники можно, выделив их в поле источников и нажав клавишу Delete.
Добавлять веб-ссылки можно:
- перетаскиванием мышью (Drag & Drop)
.url-файлов* в поле источников; - через специальный диалог добавления веб-ссылок
«Файл > Добавить веб-ссылки (URL)… (Ctrl+L)»; - через буфер обмена: скопируйте в буфер обмена адреса Web-страниц (разделенные переводом строки, если ссылок больше одной) и вставьте их в поле ввода источников
«Файл > Добавить из буфера обмена (Ctrl+V)».
Если необходимо обработать большое количество веб-страниц, отличающихся лишь индексом, то такой веб-адрес можно добавить в формате: http://www.site.com/book?page=[[1-31]], где числа в двойных квадратных скобках 1-31 — индекс первой и последней страницы, подлежащих обработке. Данный адрес будет автоматически преобразован утилитой в последовательность ссылок:
http://www.site.com/book?page=1
http://www.site.com/book?page=2
…
http://www.site.com/book?page=31
Поскольку веб-страницы хранятся не на локальном компьютере, а на удаленных серверах в Интернете, то обработка таких источников может происходить значительно медленнее, чем обработка локальных RTF- или FB2-файлов. Поэтому Вы можете отказаться от обработки веб-ссылок в текущей сессии поиска, сняв флажок «Обрабатывать веб-ссылки».
* «Ярлык Интернета Windows» (.url) — это файл, получаемый операцией Проводника Windows «Создать > Ярлык…».
Чтобы начать процедуру извлечения, нажмите кнопку СТАРТ (клавиша Enter); чтобы прервать процедуру извлечения, нажмите СТОП (клавиша Enter). По окончании процедуры выборки будет автоматически сгенерирован временный файл в формате RTF с временным названием, который, — если результат выборки Вас устраивает, — Вы можете сохранить в нужное Вам место.
Все заданные пользователем параметры поиска (запрос, источники и опции) можно сохранить в файл в формате .tex для повторного открытия в будущем: «Сохранить настройки… (Ctrl+S)».
Данный файл можно также использовать в качестве «контейнера» источников: если поместить его в любую папку, подлежащую обработке программой, то утилита обработает все источники из файла .tex так, как будто они были добавлены в поле источников непосредственно.
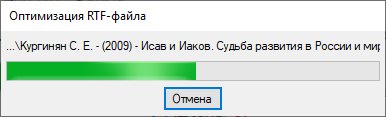
Программа работает только с файлами в формате RTF, текст в которых представлен символами ANSI или UTF8. Если же содержимое закодировано escape-последовательностями (а в таком виде RTF-файлы сохраняет Microsoft Word), то перед анализом подобного файла TEXtractor преобразует и сохранит его в более «лёгкий» ANSI-формат (сохранив оригинал в файл с расширением .backup).